





1.简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口操作ES,也可以利用Java API。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
更多了解可以上ElasticSearch官方网站:
https://www.elastic.co/cn
2.ElasticSearch的安装
2.1.安装包下载
进入ElasticSearch下载页面
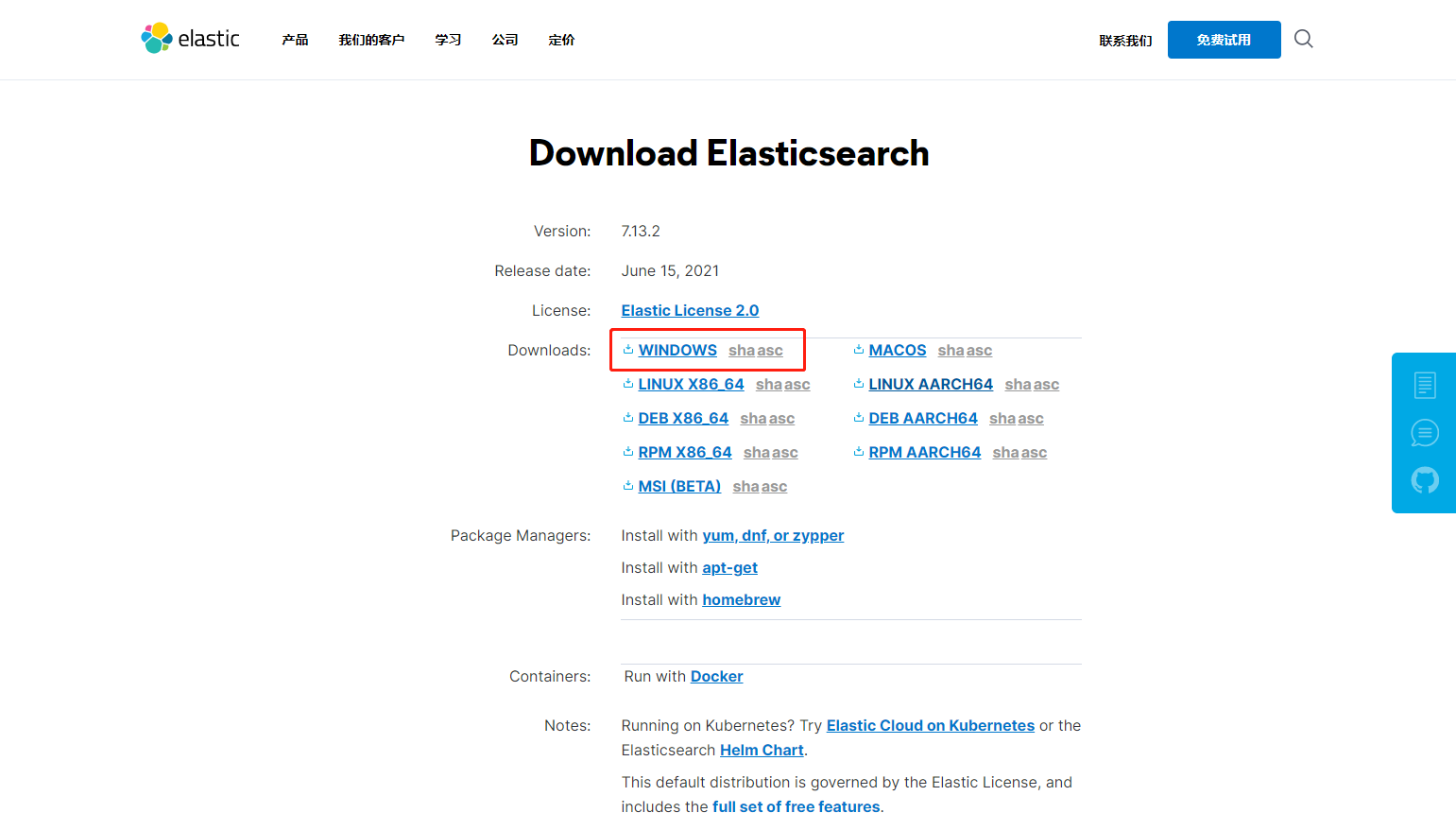
我这里选择Windows版本,
下载后得到elasticsearch-7.13.2-windows-x86_64.zip
2.2.安装
1.解压elasticsearch-7.13.2-windows-x86_64.zip压缩包
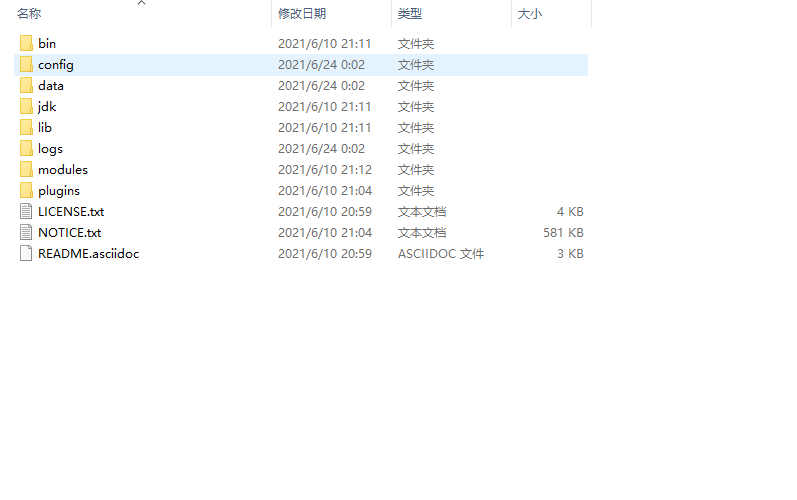
2.文件夹介绍
bin 可执行文件
config 配置文件
data 数据目录
jdk 内置java环境
lib 依赖库
logs 日志
modules 模块
plugins 插件
2.3.启动运行
双击执行bin目录下的elasticsearch.bat
cd bin
.\elasticsearch.bat
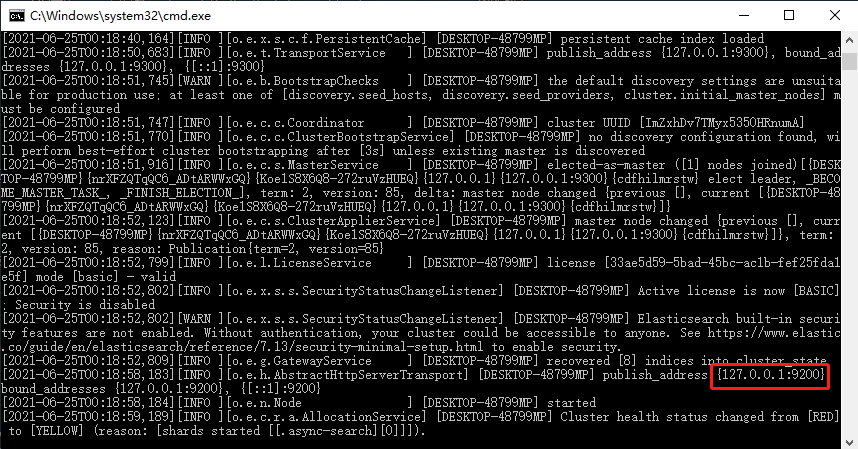
启动成功后,我们可以看到一个黑窗口
2.4.访问测试
从上面截图我们可以看到,es启动后会开启一个9200、9300端口。
我们用浏览器访问一下 http://localhost:9200 试试吧!
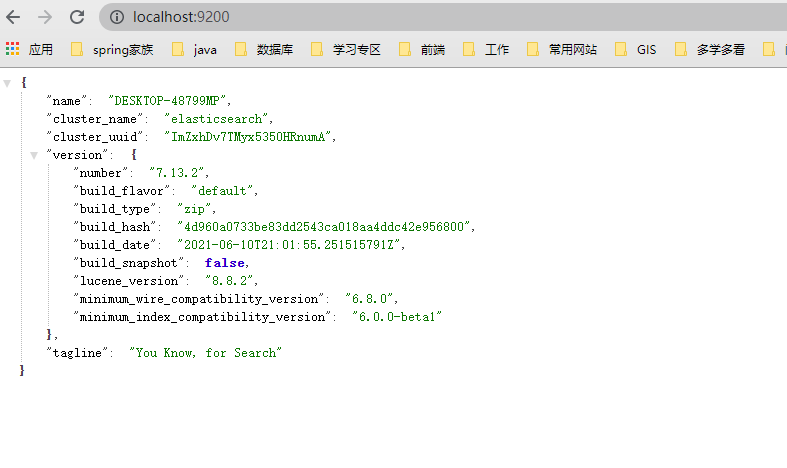
出现以上图样,说明我们的es已经启动成功啦!
3.入门 RESTful API
Elasticsearch是面向文档形数据库,一条数据在这里就是一个文档。为了方便大家理解,我将Elasticsearchl里存储文档数据和关系型数据库MySQL存储数据的概念进行一个类比
| Elasticsearch | Index(索引) | Type(类型) | Documents(文档) | Fields(字段) |
|---|---|---|---|---|
| MySQL | Database(数据库) | Table(表) | Row(行) | Column(列) |
3.1.索引操作
3.1.1.索引-创建
对比关系型数据库,创建索引就等同于创建数据库
创建方式如下:
PUT请求访问 http://es ip:9200/{索引名}
下面在Postman中,向ES服务器发送PUT请求示例:http://localhost:9200/shopping
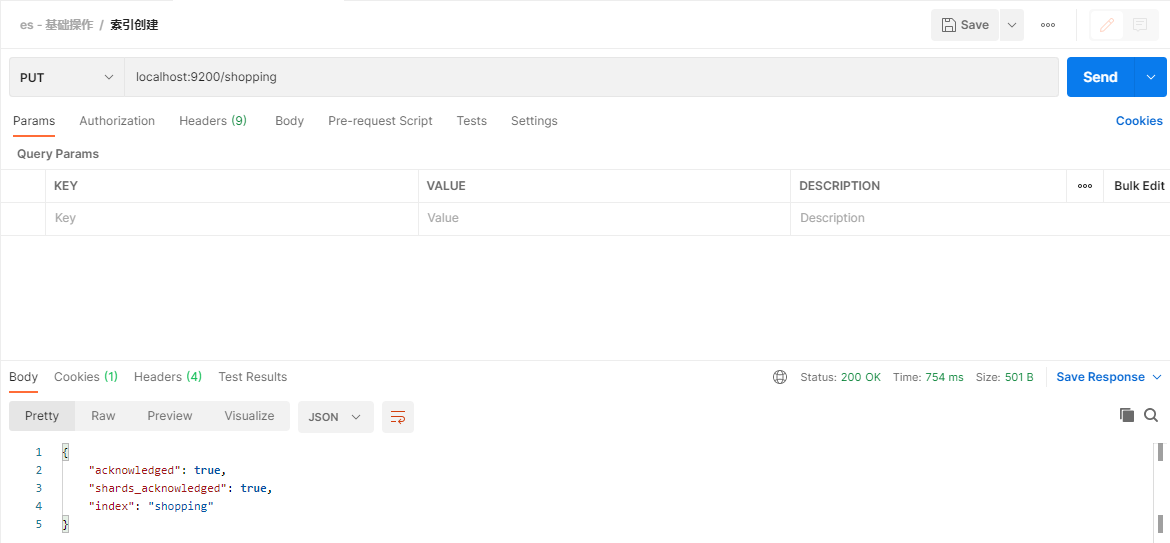
响应如上图,就说明索引创建成功
3.1.2.索引-查询
1.查询单个索引信息
查询方式如下:
GET请求访问 http://es ip:9200/{索引名}
下面在Postman中,向ES服务器发送GET请求示例:http://localhost:9200/shopping
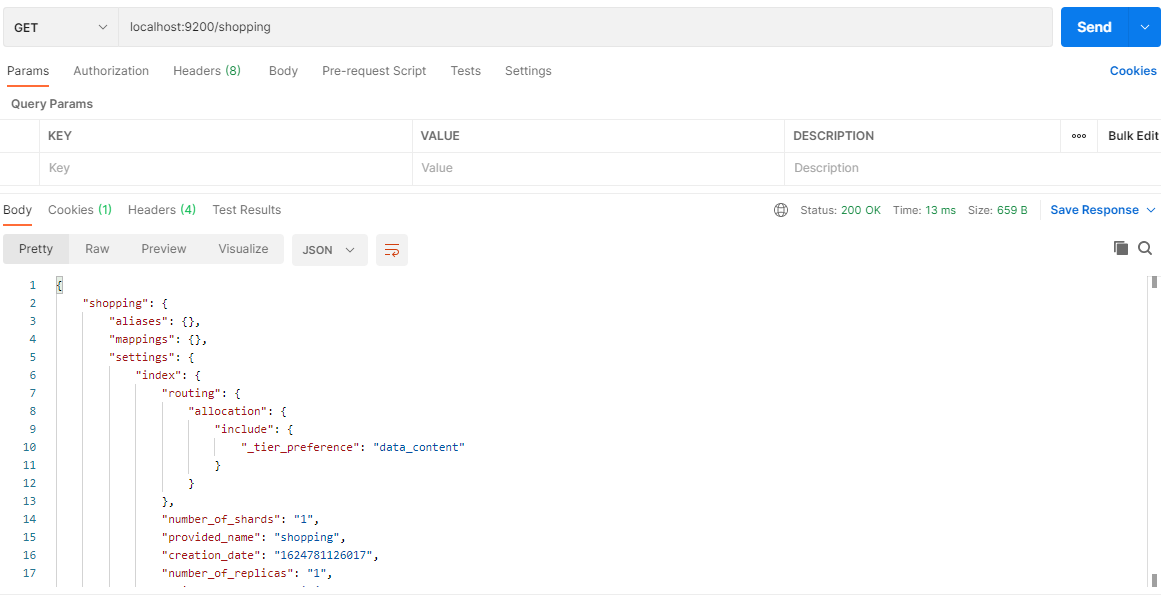
2.查询全部索引
查询方式如下:
GET请求访问 http://es ip:9200/_cat/indices
下面在Postman中,向ES服务器发送GET请求示例:
http://localhost:9200/_cat/indices
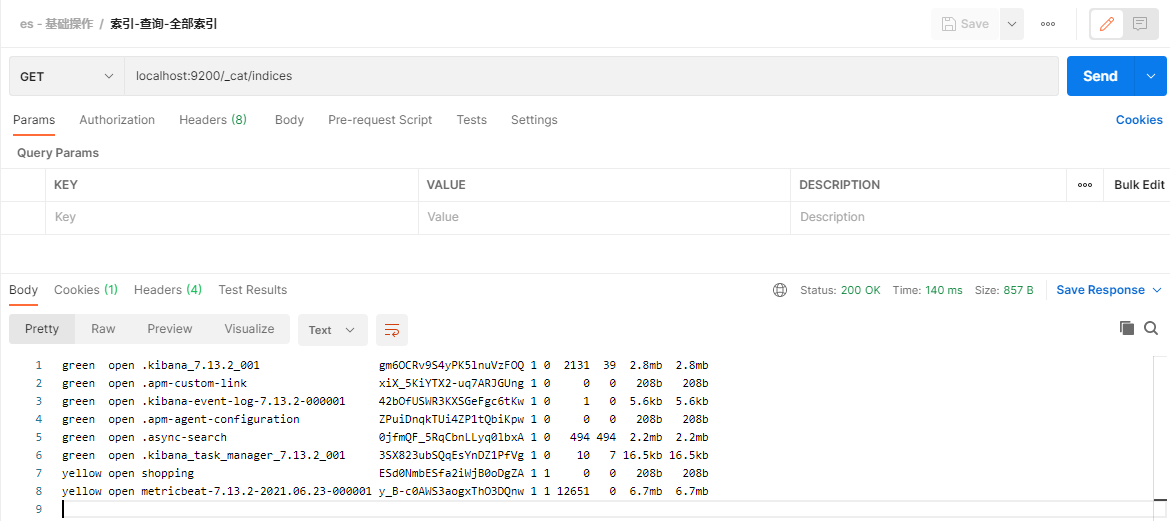
3.1.3.索引-删除
删除方式如下:
DELETE请求访问 http://es ip:9200/{索引名}
下面在Postman中,向ES服务器发送DELETE请求示例:http://localhost:9200/shopping
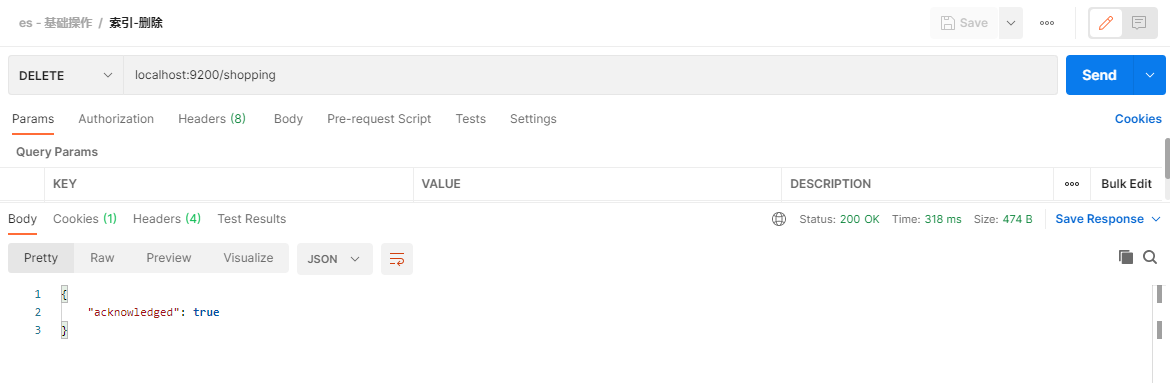
3.2.文档操作
3.2.1.文档-创建
索引创建好了,接下来我们创建文档,并添加数据,这里的文档可以类比为关系型数据库中的表数据,添加数据格式为JSON格式
创建方式如下:
1.不指定ID创建(id由es自动生成)
POST请求访问 http://es ip:9200/{索引名}/_doc Content-Type:application/json
{
"title":"小米手机",
"category":"小米",
"images":"http://www.xiaomi.com/xm.jpg",
"price":3999.00
}
2.指定ID创建
POST/PUT 请求访问 http://es ip:9200/{索引名}/_doc/{id} Content-Type:application/json
{
"title":"小米手机",
"category":"小米",
"images":"http://www.xiaomi.com/xm.jpg",
"price":3999.00
}
下面在Postman中,向ES服务器发送POST请求示例:
POST请求访问 http://es ip:9200/shopping/_doc
请求内容为:
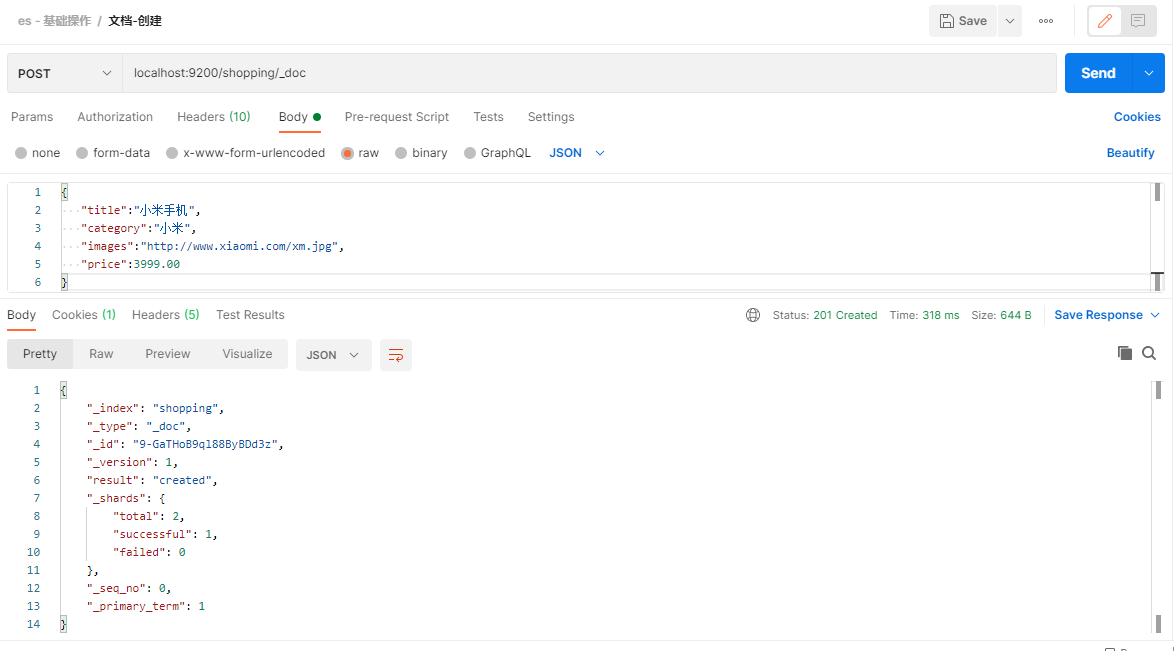
3.2.2.文档-查询
3.2.2.1.文档-主键查询
查询方式如下:
GET请求访问 http://es ip:9200/{索引名}/_doc
下面在Postman中,向ES服务器发送GET请求示例:
GET请求访问 http://es ip:9200/shopping/_doc/1
请求内容为:
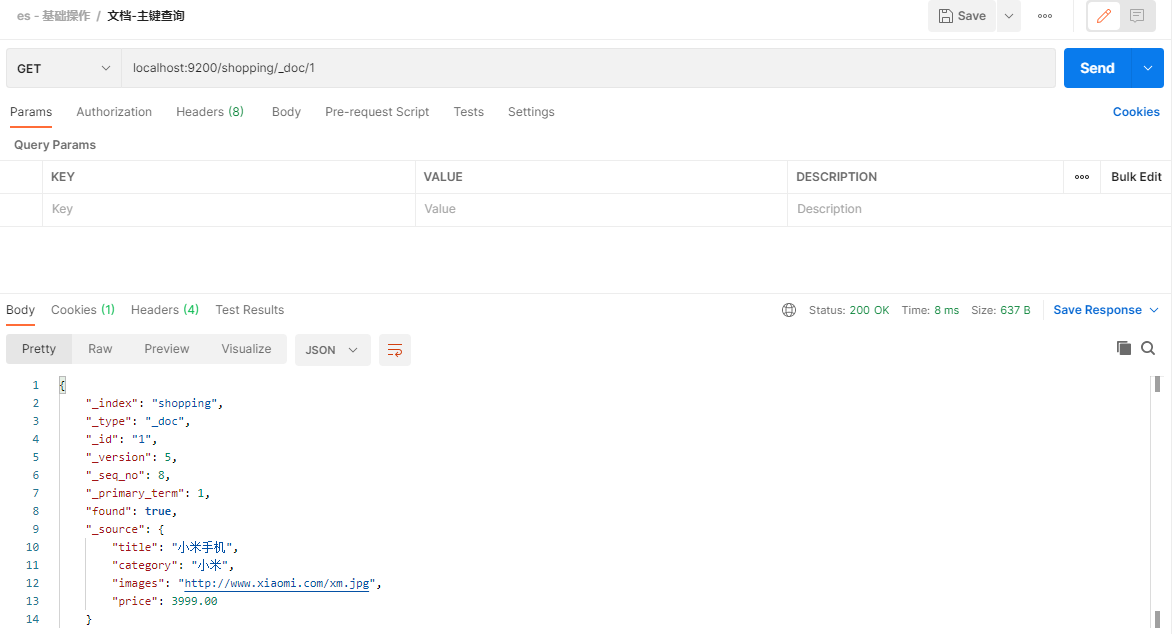
3.2.2.2.文档-条件查询&分页查询
匹配(Match)查询属于全文(Fulltext)查询,不同于词条查询,ElasticSearch引擎在处理全文搜索时,首先分析(analyze)查询字符串,然后根据分词构建查询,最终返回查询结果。匹配查询共有三种类型,分别是布尔(boolean)、短语(phrase)和短语前缀(phrase_prefix),默认的匹配查询是布尔类型,这意味着,ElasticSearch引擎首先分析查询字符串,根据分析器对其进行分词,例如,对于以下match查询:
{
"query":{
"match":{
"title":"小米手机"
}
}
查询字符串是“小米手机”,被分析器分词之后,产生三个小写的单词:小,米和手机,然后根据分析的结果构造一个布尔查询,默认情况下,引擎内部执行的查询逻辑是:只要title字段值中包含有任意一个关键字小、米或手机,那么返回该文档,伪代码是:
if (doc.title contains "小" or doc.eventname contains "米" or doc.eventname contains "手机")
return doc
匹配查询的行为受到两个参数的控制:
operator:表示单个字段如何匹配查询条件的分词
minimum_should_match:表示字段匹配的数量
通过调整operator 和 minimum_should_match 属性值,控制匹配查询的逻辑条件,进而控制引擎返回的结果。默认情况下operator的值是or,在构造查询时设置分词之间的逻辑运算符,如果设置为and,那么引擎内部执行的查询逻辑是:
if (doc.eventname contains "小" and doc.eventname contains "米" and doc.eventname contains "手机")
return doc
对于minimum_should_match 属性值,默认值是1,如果设置其值为2,表示分词必须匹配查询条件的数量为这意味着,只要文档的eventname字段包含任意两个关键字,就满足查询条件。
短语(Phrase)是一个字符串,其单个分词出现的位置和分词的数量是固定的。在进行短语查询时,必须匹配短语中每个分词及其相对位置,例如,对于包含两个分词的短语:“小米手机”,分词“小米”出现在分词“手机”之前,并且两个词条之间的位置相差一个空格,下面两个字符串都满足短语匹配:
"小米手机真好用"
"小米手机好好用"
一,布尔匹配查询
1.布尔型match查询是把query参数中的条件字符串加以分析,使用索引映射中定义的分析器对字符串分词,然后构建相应的子查询,ElasticSearch选择合适的分析器(analyzer),该analyzer和建立索引时使用的分析器相同。在执行match查询时,默认情况下,字段值必须匹配任意一个词条,例如,当文档的title字段匹配任意一个分词,小、米和手机时,该文档匹配match查询,匹配分词的数量是由匹配参数控制的。
{
"from":10,
"size":5,
"query":{
"match":{
"title":"小 米 手机"
}
}
}
2,match查询常用的参数
operator:用来控制match查询匹配词条的逻辑条件,默认值是or,如果设置为and,表示查询满足所有条件;
minimum_should_match:当operator参数设置为or时,该参数用来控制应该匹配的分词的最少数量;
{
"from":10,
"size":5,
"query":{
"match":{
"title":{
"query":"小 米 手机",
"operator":"or",
"minimum_should_match":2
}
}
}
}
二,短语匹配查询(match_phrase)
在执行短语匹配查询时,ElasticSearch引擎首先分析(analyze)查询字符串,从分析后的文本中构建短语查询,这意味着必须匹配短语中的所有分词,并且保证各个分词的相对位置不变:
{
"from":1,
"size":100,
"fields":[ "title"],
"query":{
"match_phrase":{
"title":"小米手机"
}
}
}
三,短语前缀匹配查询(match_phrase_prefix)
除了把查询文本的最后一个分词只做前缀匹配之外,match_phrase_prefix和match_phrase查询基本一样,参数 max_expansions 控制最后一个单词会被重写成多少个前缀,也就是,控制前缀扩展成分词的数量,默认值是50。扩展的前缀数量越多,找到的文档数量就越多;如果前缀扩展的数量太少,可能查找不到相应的文档,遗漏数据。如代码所示,能够查到eventname包含"Open Source Hack Night"的文档。
{
"from":1,
"size":100,
"fields":[ "title" ],
"query":{
"match_phrase_prefix":{
"title":{
"query":"小米手机",
"max_expansions":50
}
}
}
}
四,多字段匹配查询
在多个字段上执行匹配相同的查询,叫做"multi_match"查询,Elasticsearch共有五种多字段匹配查询:best_fields,most_fields,cross_fields,phrase和phrase_prefix,默认的是best_fields类型,如下示例代码:
{
"query": {
"multi_match": {
"query": "小米",
"fields": [
"title",
"category"
]
}
}
}
参数query指定查询的条件,在match查询中,query中的参数被分析成分词;参数type指定查询的类型,默认值是best_fields;参数fields指定字段数组,ElasticSearch在每个字段上匹配参数query。对于best_fields和most_fields类型,每个字段都会拆分成一个子查询(Individual Query),这意味着,ElasticSearch引擎在每个字段上生成一个子查询,每个子查询都匹配相同的query参数。
在示例中,参数query被拆分成两个分词microsoft和azure,ElasticSearch引擎有两个参数设置每个子查询(Individual Query)应该匹配的分词数量。
参数operator设置每个字段的子查询的匹配分词的逻辑方式,默认值是or,例如,如果设置参数operator为and,那么subject字段中必须同时含有microsoft和azure这两个分词。也就是说,匹配所有的分词。
"operator":"and"
当参数operator使用默认值时,参数minimum_should_match设置每个子查询应该匹配多少个分词,默认值是1,例如,设置minimum_should_match为1,那么subject字段中至少含有microsoft或azure的一个分词。
“operator”:"or"
"minimum_should_match":1
1,best_fields类型
best_fields类型是默认值,从指定的字段中匹配查询,每个字段都计算评分(_score),返回最高的评分。如果不考虑评分,那么best_fields查询类型的含义是从指定的字段中执行查询,返回匹配的文档。
对于best_fields和most_fields查询类型,它们都是基于字段拆分的,每个字段都会产生一个子查询,
{
"multi_match" : {
"query": "小米手机",
"type": "best_fields",
"fields": [ "title", "category" ],
"operator": "and"
}
}
跟best_fields类型相同的查询类型是dis_max,字母dis是单词“Disjunction”的简写,意思是分离,dis_max查询类型有一个子查询数组,每一个子查询都单独计算评分,返回子查询中最高的评分。如果忽略评分,那么dis_max查询类型的含义是执行指定的子查询,返回匹配的文档。
{
"dis_max": {
"queries": [
{ "match": { "subject": "brown fox" }},
{ "match": { "message": "brown fox" }}
]
}
}
2,most_fields类型
most_fields类型是默认值,从指定的字段中匹配查询,每个字段都计算评分(_score),最后把每个字段的评分合并(Combine)在一起,求平均分。如果不考虑评分,那么most_fields查询类型的含义是从指定的字段中执行查询,返回匹配的文档。
该类型的查询类似于布尔查询的should子句查询,
{
"bool": {
"should": [
{ "match": { "title": "quick brown fox" }},
{ "match": { "title.original": "quick brown fox" }},
{ "match": { "title.shingles": "quick brown fox" }}
]
}
}
3,phrase和phrase_prefix查询类型
该类型的query是phrase,在每个字段上执行查询,然后返回最高的评分,类似于best_fields类型。
4,cross_fields类型
该查询类型是把query条件拆分成各个分词,然后在各个字段上执行匹配分词,默认情况下,只要有一个字段匹配,那么返回文档。
例如,query参数拆分成will和smith两个分词,当参数operator为and时,字段first_name或last_name必须包含will ,并且 first_name或last_name必须包含smith。
{
"multi_match" : {
"query": "Will Smith",
"type": "cross_fields",
"fields": [ "first_name", "last_name" ],
"operator": "and"
}
}
如果参数operator为or,字段first_name或last_name必须包含will ,或者 first_name或last_name必须包含smith,其等价的逻辑是,只要字段 first_name或last_name中包含 will或smith就返回文档。
下面写个实例请求
POST localhost:9200/shopping/_search Content-Type:application/json
{
"from": 0, //第几号开始
"size": 10, //显示多少条
"query": {
"match": {
"title": {
"query": "小 华 手机",
"operator": "or",
"minimum_should_match": 2
}
}
}
}
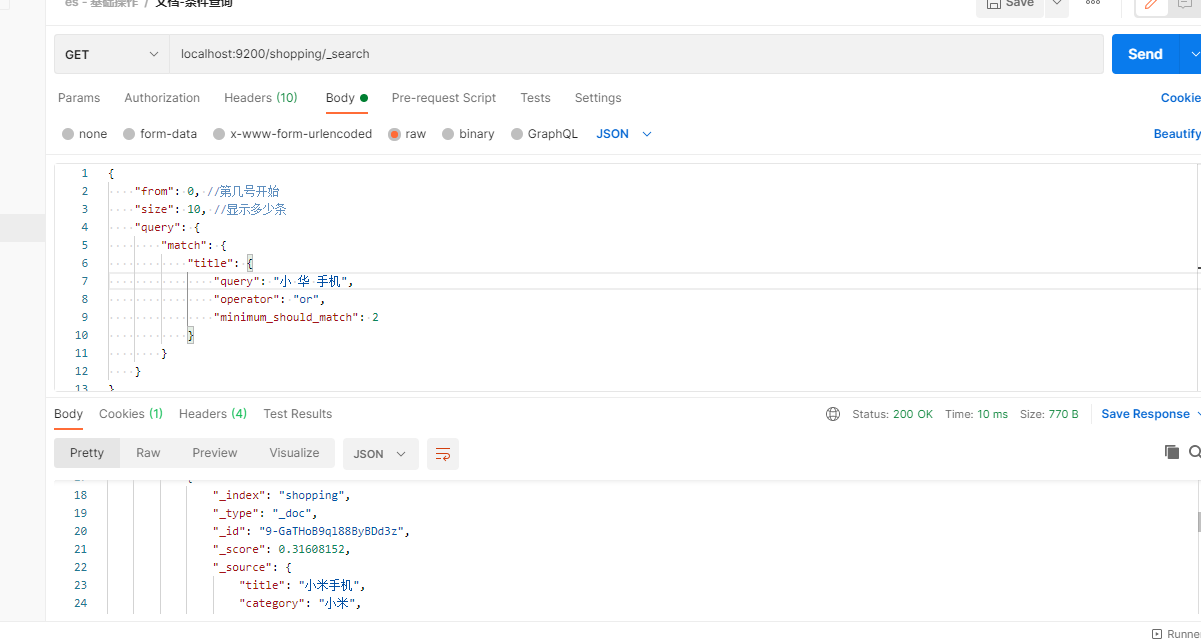
3.2.3.文档-更新
文档修改,在es中分为两种:1.完全修改,2.局部修改
修改方式如下:
1.完全修改
POST/PUT请求访问 http://es ip:9200/{索引名}/_doc/{id} Content-Type:application/json
{
"title":"小米手机",
"category":"小米",
"images":"http://www.xiaomi.com/xm.jpg",
"price":5999.00
}
2.局部修改
POST/PUT 请求访问 http://es ip:9200/{索引名}/_doc/{id}/_update Content-Type:application/json
{
"doc": {
"title": "华为手机",
"category": "华为"
}
}
完全修改
下面在Postman中,向ES服务器发送POST请求示例:
POST请求访问 http://es ip:9200/shopping/_doc/1
请求内容为:
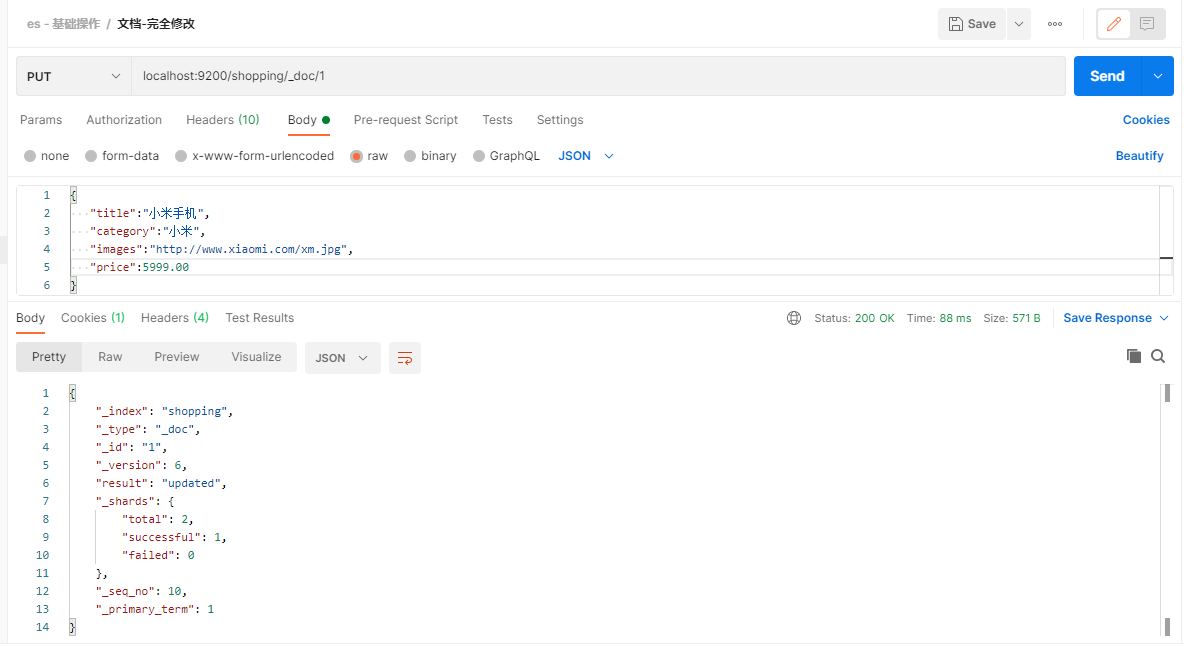
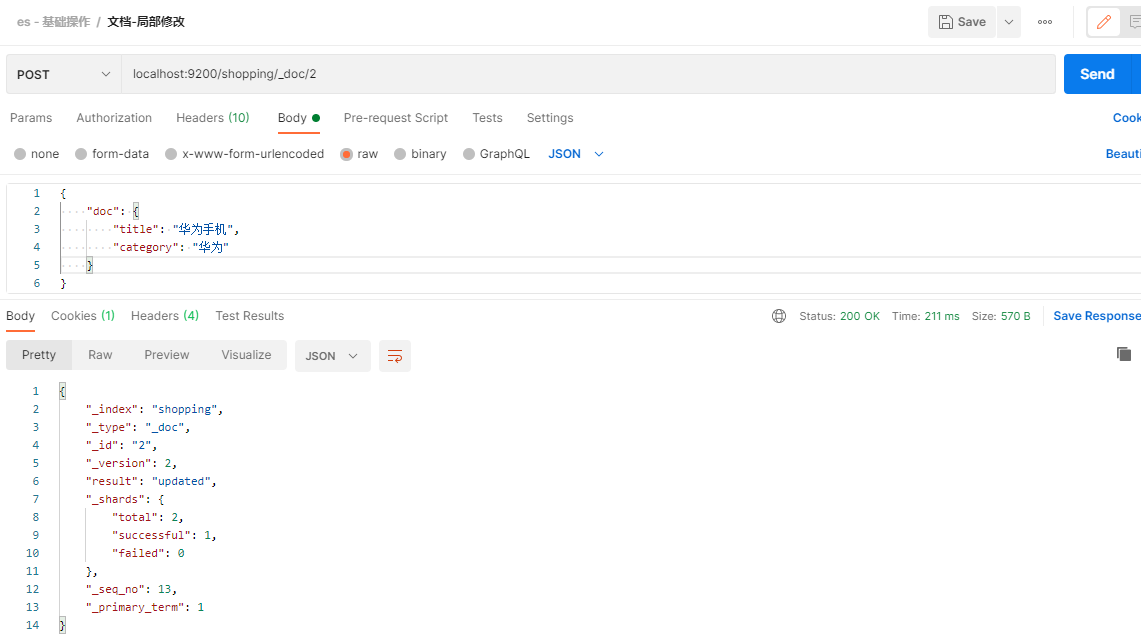
局部修改
下面在Postman中,向ES服务器发送POST请求示例:
POST请求访问 http://es ip:9200/shopping/_doc/1/_update
请求内容为:
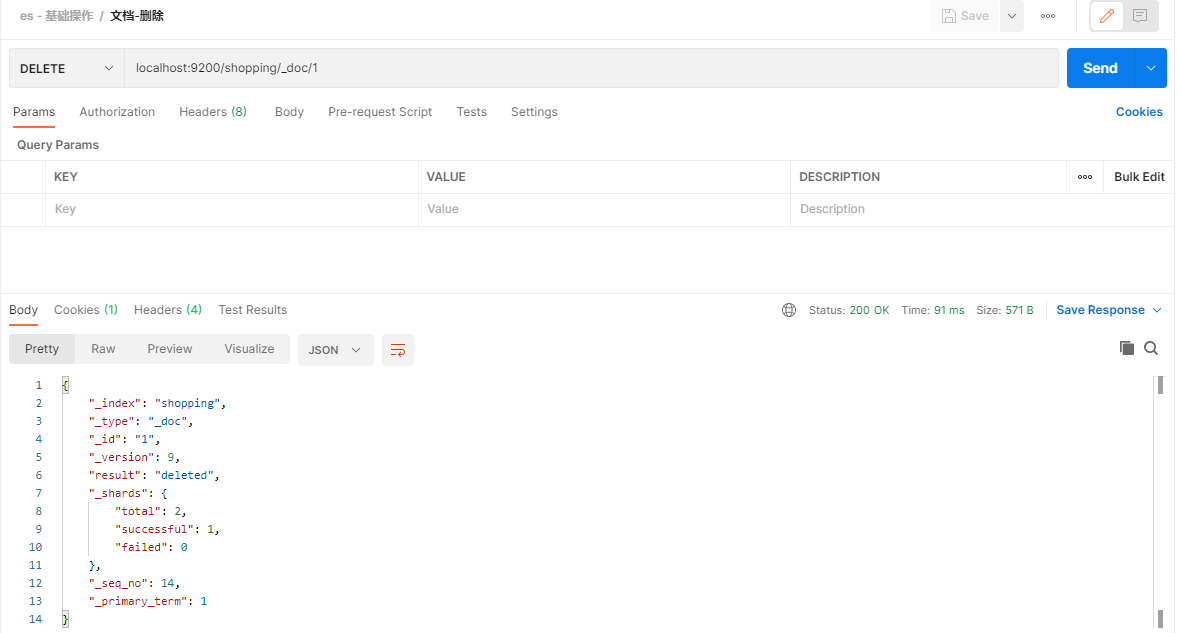
3.2.4.文档-删除
删除方式如下:
DELETE请求访问 http://es ip:9200/{索引名}/_doc/{id}
下面在Postman中,向ES服务器发送DELETE请求示例:http://localhost:9200/shopping/_doc/1
Q.E.D.